We propose ChatVLA-2, a novel VLA model enables generalized open-world embodied reasoning and reasoning following abilities.
We argue that a generalizable VLA model should retain and expand upon the VLM's core competencies: 1) Open-world embodied reasoning - the VLA should inherit the knowledge from VLM, i.e., recognize anything that the VLM can recognize, capable of solving math problems, possessing visual-spatial intelligence, 2) Reasoning following – effectively translating the open-world reasoning into actionable steps for the robot. In this work, we introduce ChatVLA-2, a novel mixture-of-expert VLA model coupled with a specialized two-stage training pipeline designed to preserve the VLM's original strengths while enabling actionable reasoning.
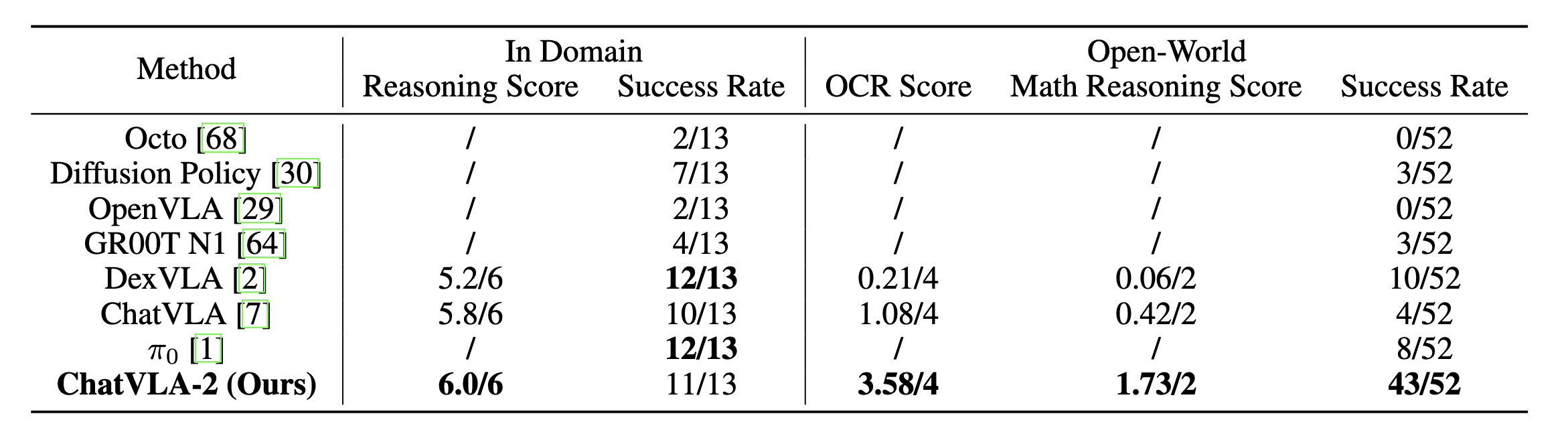
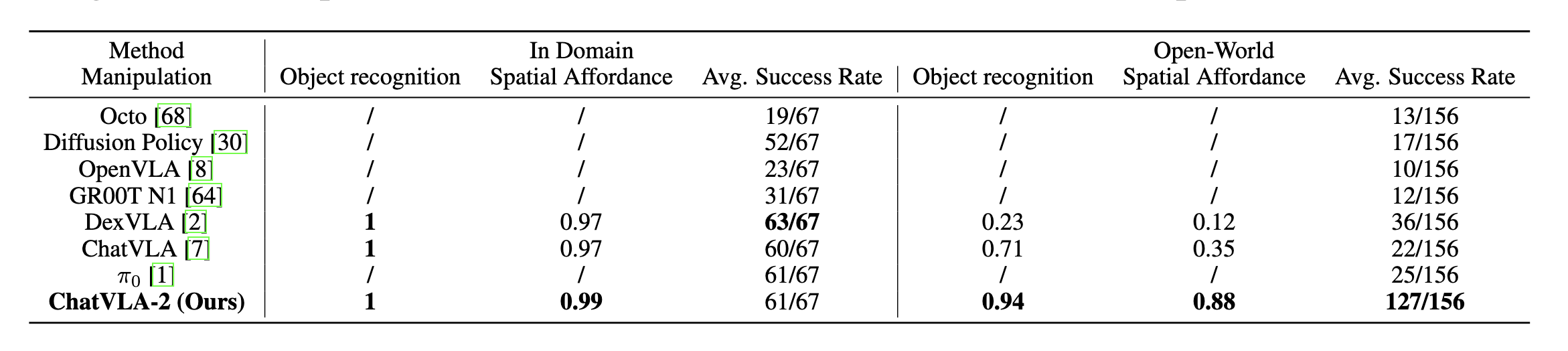
To validate our approach, we design a math-matching task wherein a robot interprets math problems written on a whiteboard and picks corresponding number cards from a table to solve equations. Remarkably, our method exhibits exceptional mathematical reasoning and OCR capabilities, despite these abilities not being explicitly trained within the VLA. Furthermore, we demonstrate that the VLA possesses strong spatial reasoning skills, enabling it to interpret novel directional instructions involving previously unseen objects. Overall, our method showcases reasoning and comprehension abilities that significantly surpass state-of-the-art imitation learning methods such as OpenVLA, DexVLA, and \(\pi_0\). This work represents a substantial advancement toward developing truly generalizable robotic foundation models endowed with robust reasoning capacities.